Getting Productive with XMLMind
June 21, 2007
Background
What do you use when you need to edit large technical documents with complex structure and cross-references? The answer used to be very easy: FrameMaker. We encountered this powerful, multiplatform authoring tool back in the '80s on Sun workstations, and were happy to continue taking advantage of it on Macs when writing our first books for O'Reilly. But FrameMaker has not been treated kindly of late. When Frame Technology stumbled in the '90s, cannibalizing its technical publishing market by trying to expand into the professional market, Adobe acquired the product, largely due to strong interest from Adobe co-founder John Warnock. But he retired from active involvement in the company before he could convince anyone else of the unique value in FrameMaker, which has since withered from neglect (it won't even run on current Macintosh systems).
So what do you use instead? Presentation-focused editors like Word are completely inadequate to this kind of task. For some time, things looked increasingly desperate. We hung on, running old FrameMaker versions in Apple's Classic OS emulation mode (which works only on older PowerPC hardware). Happily, an alternative has emerged based on the DocBook XML format, an open standard for representing technical documentation. There is a growing tool chain for this format, with a family of editors and processors that can format output as HTML or for print.
One editor stands out from the pack. The XMLmind XML Editor (XXE for short) is a great general-purpose XML editor, but has surprisingly powerful support for working with DocBook materials in an author-friendly way. We were introduced to it by the Tools group at O'Reilly, and once we got the hang of it, started feeling hopeful and enthusiastic about the future of technical writing software again. While it's not perfect, it's a lot better than we expected, and seems to be growing fast.
We should also note that the generous terms of the free standard edition license, which helped it spread like wildfire among our coauthors and colleagues, have been greatly reduced recently, which is disappointing. (This is discussed in an open letter from O'Reilly.) In fairness, though, we were happy to pay for FrameMaker when we needed it, so even if you don't have a copy of the old Standard Edition of XMLmind that you can freely use for writing your books and articles, you should consider experimenting with the new Personal Edition, and if you find it as useful as we do, purchasing a Professional Edition license.
Like any powerful tool, of course, there are some details and techniques that you need to learn before you feel proficient and can focus on your actual goals rather than figuring out how to wield the tool in a way that helps rather than hindering. This article tries to leverage our own learning struggles (which happened recently enough that we can remember them well) to make your own learning process faster and more pleasant. So if you decide to adopt XMLmind for your technical writing (and we certainly hope you do), here are some pointers that should help.
Basic Orientation
The trickiest thing to get used to, we think, is how context-sensitive everything is. The kinds of nodes you can add as siblings or children are completely dependent on what you have selected, and at a particular point in the text you can select the whole hierarchy of parent nodes. Learning to tell where you are, and get to where you want to be, can make a huge difference.
Here are some key elements of the interface we'd like to call to your attention:

Figure 1. Basic XMLmind navigation elements
The Node Path bar (bullet 1) is similar to an XSLT path expression, showing exactly
what
you have currently selected (or where your insertion point is, as in this case). A
very
handy shortcut is that you can click any element of the path with your mouse to select
it.
For example, if we click the emphasis element, we see the following result:

Clicking on the para node yields this instead:

See the Node Path bar section of the online help for some other neat things you can do with this powerful interface element.
You can also traverse up and down the node hierarchy using the movement buttons (bullet 2) or their corresponding keyboard shortcuts (Control-Up or -Down to move to parents and children, and Control- Shift-Up or -Down to move to adjacent siblings; as usual, if you're on a Mac, use the Option key rather than Control, since XMLmind does a really good job of showing that a comfortable Mac application can be written in cross-platform Java). Try playing with these and looking at the visual feedback.
To get an alternate view of what is going on, switch away from the nice WYSIWYG DocBook view to the actual document structure by choosing 0 (no style sheet)in the View menu:
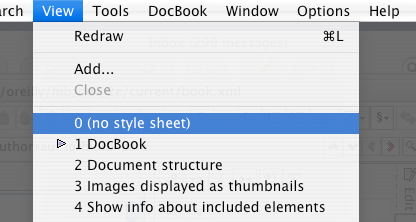
This gives you a tree view of the document, which is often useful when you are focusing on structural organization more than the raw content:

Figure 2. The document in Tree View
Try exploring the other view choices, which are also useful in other contexts. (We just learned that you can have multiple views open at once by choosing the Add... option in the View menu! When we are on a large screen, we'll probably keep both the DocBook and structural views open side-by-side most of the time now.)
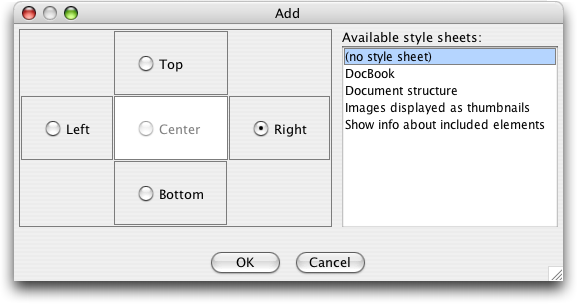
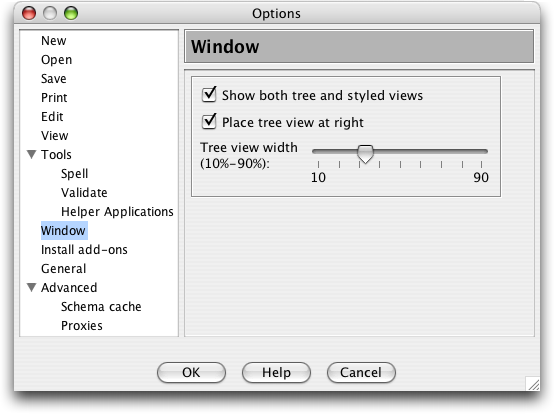
And later we learned that, despite the intense flexibility of view configuration offered by the above dialog, there is an even easier way to get side-by-side styled and tree views as a default. This is found in the Window pane of the Preferences (or Options, depending on your platform menus) dialog:
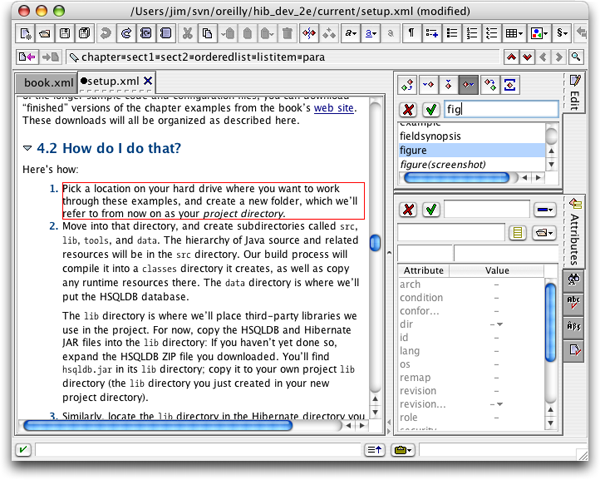
Recall why we started this discussion about structure and selection: It very much affects the behavior of the application. Bullet 3 in Figure 1 points out a set of very useful buttons that lets you insert a new XML element into, before, or after your selection, change the current node to a different kind that fits there, or wrap it with another node. It's definitely worth experimenting with these capabilities a bit and getting good at them. When you click on one of them, the interface below will show you the legal choices for elements for the operation you're trying to perform (and you can type leading characters to jump to the one you want if there are many legal choices). If you don't see the choice you expect (or the buttons are completely disabled), you are probably at the wrong depth in the XML hierarchy, so either Control-Up or -Down to get to the right place, or click on the right node in the path. Here we're about to insert a figure after a list item:
There are similarly a variety of paste options whose validity depend on what you are pasting and what element you have selected. Bullet 4 in Figure 1 is next to the Paste Before, Paste, and Paste After buttons; these are very useful and highly context-sensitive. The fundamental thing to keep in mind, though, is that if you've copied something and don't seem to be able to paste it, try navigating up and down the tree until you have an element of the corresponding type selected, and then you should be able to paste. (Using the keyboard is often faster than the mouse, so don't forget about Control-Up and -Down.) And remember that you'll sometimes face more stringent matching restrictions if you are pasting to replace selected elements rather than pasting before or after them.
This does get easier to understand and predict with practice and familiarity, so don't despair, even if it often feels like voodoo to start with.
Finally, we suggest you explore the formatting buttons (bullet 5). These provide a semantically focused styling mechanism for identifying a span of text as a filename, a literal, a term being defined, and the like. While you can explicitly request emphasis for its own sake, it's usually better to mark up the text in a way that identifies exactly what it is, then your stylesheet can decide how to represent it in a way that is appropriate for your output medium and organizational standards. As you'll see when playing with it, that's the focus of the emphasis menu in XMLmind.
And keep in mind that not all useful style choices are available through these menus;
for
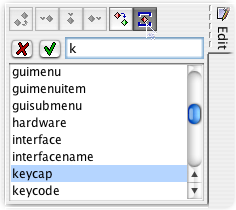
example, the keycap style is good for talking about keyboard commands, and
there's no shortcut for it. An easy way to apply it is to select the word you want
to style,
then click the Convert [wrap] button (right next to bullet 3 in Figure 1), type K in the Edit tool
underneath, and then Enter(or Return depending on your keyboard) to accept the
keycap element (which will be the highlighted choice, since it's the first
legal element whose name starts with k):
We're about to dive into deeper topics, but this should hopefully help you get started in a useful way. UNC-Chapel Hill also has a nice two-page introduction to using the editor, and of course you can use the built-in help to dig deeper into things we glossed over here.
Tables
OK, so tables are straightforward, albeit clunkier than you'd like. Here are a few pointers.
Use the Add table button in the main tool bar to insert a table. This is easiest when you're in a simple paragraph (at whatever level of section) but I think there are other places that work too, like in a list.
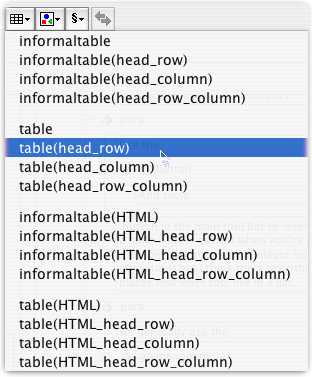
We generally use the table(head_row) option in the button's drop-down menu:
Like figures (Figures and Screen Shots), equations, and examples,
DocBook tables come in two varieties: normal and informal. The normal, formal table
has a
caption with a table number, and so works very well with cross-references (also explained
below). If you just need a little inline, throwaway table, you can use
informaltable. When you are working with DocBook documents (which is what
we're writing about), always use the top two sections, rather than the HTML tables
which
make up the second half of the drop-down menu.
Within each type of table, the four choices in the menu set up different initial structures. Your table can have just body cells, or it can have a row or column (or both) designated as header cells. You can set up this structure by hand; later on, but having options that create it in one step is definitely convenient. Our tables usually have header rows, which is why we usually choose table(head_row).
To add a column: DocBook -> Column -> Insert After (or Before)
To add a row: DocBook -> Row -> Insert After (or Before)
Be sure to add an id to the table (unless you're creating an informal one).
You might end up with anchors on interesting rows of the table as well, but cross
references
(see Cross References) to the table itself need to go to the
id associated with the top level table element, which will allow
the cross reference mechanism to pull out the table's label or caption as desired
by the
cross-reference creator. Here's an easy way to do it.
Make sure the table element itself is selected. If you've just created the
table, it will be. Otherwise, it's probably easiest to click the table element
in the Node Path bar (bullet 1 in Figure 1). You can always
double-check by glancing there and at the tree view, if you have it showing. With
the table
element selected, type in a unique value for its id attribute in the Attributes
tool on the right.
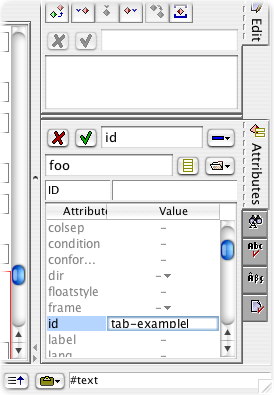
In this case, we're assigning a value of tab-example to the table's
id attribute. We prefix the id with tab-, but you
may prefer another convention. Establishing a convention for naming elements that
may be the
target of cross-references later on (see Cross References) is a very good idea though. We find using a
prefix based on the element's type like this definitely makes it easier to dig through
the
drop-down list of available IDs in the Attribute tool when creating xref
elements to our tables/figures/examples...
One last annoyance: the default entry/#text elements that come inside a table cell are only good for the most rudimentary content. If you simply have several columns of plain, wrappable text, you're fine. If you have any special needs (such as preformatted text or a list) you'll need to tweak the defaults.
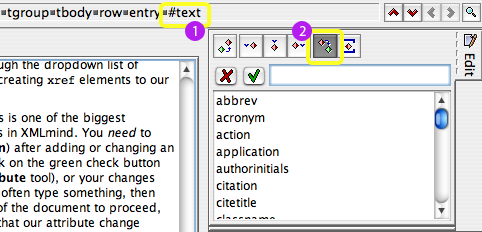
One of the quickest ways to end up with what you really want is to click on the #text
portion of the path (Bullet 1 above) and then use the Convert button (Bullet 2) to
exchange
it for something more useful. For example, in the table below, the command-line options
are
presented in a literallayout element allowing us to add internal line breaks
for readability. But you are free to use other elements like the familiar para
element (to which you can append a list, for example) or more specialized elements
like
citation or errortext.
Table 1. cap command line arguments
| Argument | Default? | Description |
|---|---|---|
|
-a |
N | An action to perform. Multiple actions are allowed and are performed in the order given. |
|
-A |
N | Sets up the minimal starting pieces inside an existing Rails application. |
|
-h |
N | Prints out a help message with descriptions of each of these options. |
|
--no-pretend |
Y | Forces the commands to be executed on the remote server. This is the default, but you might use it when you have used the pretend option for a previous action. |
|
-v |
Y | Displays verbose messages from Capistrano. |
Figures and Screenshots
Figures are similar to tables. There are a few guidelines for figures and images when working with the DocBook format. Not all output media are equal, so do keep that in mind. The guidelines presented here are aimed primarily at building downloadable PDF files, so the size and file formats you encounter may vary.
We've found the best (read most consistent and easiest to both create and publish) image format to be PNG, full color. While your publishing medium may need other formats, consider PNG for all your screenshots. O'Reilly authors should definitely use PNG for all graphics.
figs folder which is kept in the same directory as your book.xml
file. This will be required down the road by the PDF processing software. There's a button on the main tool bar that makes it easy to insert a figure. It's the button with the three geometric shapes and the tool tip reads Add Image.
For formal figures and screen shots (those that are numbered or are meant to be cross-referenced), type in a good caption for the figure, but don't include any numbering scheme; that should be handled in your stylesheet during output processing. As for the difference between figures and screenshots, we never got direct advice on this. We use the figure choice for figures we build in Illustrator or OmniGraffle, figure(screenshot) for actual screen shots that we want to be able to cross-reference, and screenshot for informal drop-in images that do not have cross-references or captions. These both produce a spot for a graphic file and a caption, but it seems likely the stylesheet author would appreciate having the ability to differentiate between the two cases during output processing.
All screen shot variations come with a separate info line (the empty light blue line in the screen shot below). You can fill in details of the screen shot there if you like, but we've never found a good, explainable use for that line. We certainly add captions to figures, but for the screenshot info line, we usually just select it in the element path and delete it. Once you have added your info or removed it altogether, double-click on the multicolored image to start the file selection process.
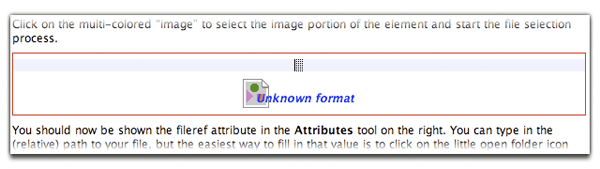
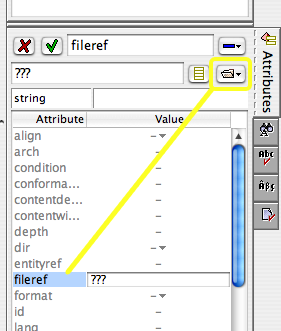
You should now see a dialog devoted to filling in the fileref attribute (you'd
normally do this in a more manual way via the Attributes tool on the right). You can
type in
the (relative) path to your file, but the easiest way to fill in that value is to
click on
the little open folder icon (highlighted below) and select your image using a normal
file
selection dialog.
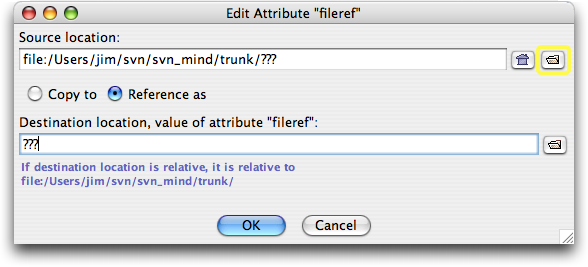
If you simply click once on the Unknown format icon, you can still supply a
fileref by using the Attributes tool as usual. A similar file chooser dialog
is available at any point from this tool as well, assuming you've properly chosen
the
figure's imagedata element and are editing its fileref attribute,
as shown below.
As with tables, you can also create formal figures if you need a caption or the ability
to
cross-reference. Be sure to set the figure's top-level id attribute, as
discussed in Tables previously. Figure 3 shows a formal image with a caption just
for reference.

Figure 3. A sample Rails deployment environment
The two other attributes and values to set for your figures are:
-
scalefit:1 -
width:5in(or whatever size is dictated by your publishing format; this example is for an O'Reilly Shortcut)
Cross-references
Cross-references are also pretty easy once you get the hang of things. An easy way
to get
started is to just put xxx in your text as you're typing and come back to
replace that chunk with a real reference after you've added the
table/figure/section/etc.
To place the actual cross-reference link, delete the xxx and place your cursor
where you want the xref/link to go.
Click the Insert button (the middle one in the section highlighted by bullet 3 back
in Figure 1) and pick the
xref element from the list of available elements in the Edit tool. (Typing X
is a fast way to jump to it.)
Supply the linkend attribute value as shown here:
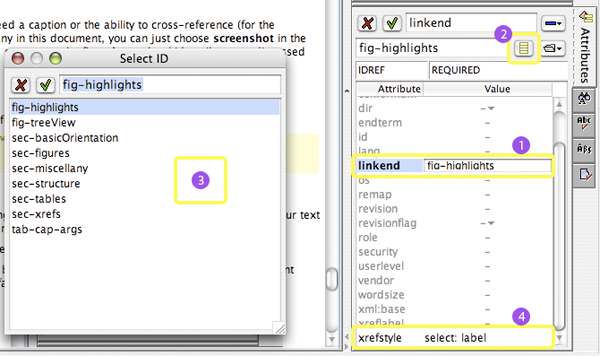
- The xref you just inserted should start out selected. If you need to (because you've done something else and are coming back to this task), select it.
- Click the
linkendattribute in the Attributes tool (bullet 1). - Pull up a list of existing
ids by clicking the List of Values button in the second row of the tool (bullet 2). - Select the desired
idfrom the dialog that pops up (bullet 3). - Also be sure to set the
xrefstyleattribute to something appropriate (bullet 4). For printed material, the usual value isselect: labelwhich generates something like Figure 3. For an online article like this without numbered sections, we've been usingselect: quotedtitleto generate section cross-references. You can see a whole bunch of other options in the excellent Sagehill book available online.
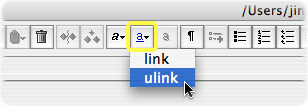
You can also embed hyperlinks to other documents out on the web, obviously, as we
just did
in the last bullet above. To do this, select the text you want to turn into a link,
then
wrap it in a ulink element using the link menu:
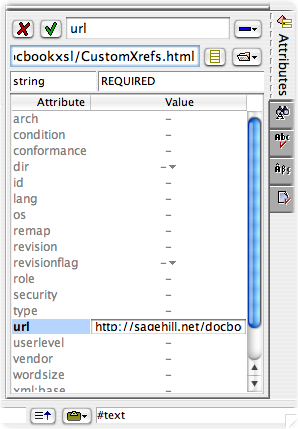
Set the url attribute of the ulink using the Attributes tool:
The link will be live in a generated HTML version of the document, and will display the URL in a printed version. The DocBook stylesheets are smart enough not to produce a redundant copy of the link if you used the URL itself as the text. Otherwise the URL will either be displayed in brackets after the text of the link, or set as a footnote, at the discretion of the stylesheet author/user. In PDF versions, the link will display the URL for printing, but will also be live when you're viewing the PDF on a computer.
DocBook Structural Elements
Most documents of any size will have structure, and if you're bothering to consider DocBook as a format, your document almost certainly qualifies. There's good support for rich structure in the format and in XMLmind. You start by adding a new section using the Section menu:
When working with DocBook, the general, nestable section choice seems to be the only
one
readily available, and I find myself unable to predict when it will add a section
at the
same level as the current one I'm working on, or a subsection, or something else.
Luckily,
it doesn't matter much because it's easy to use DocBook -> Promote and DocBook ->
Demote to
adjust it to the right level. (You'll be able to tell because of both how big the
heading
is, and how many subsection numbers it contains.) The DocBook menu also gives you
ways to
move sections up and down. These options only work if you have the actual elements
selected
(as opposed to a #text pseudoelement). The Move Up and Move Down functions can be
used to
move elements past each other in general, although they're most often useful for moving
sections around. Promote and Demote are available in fewer contexts, although as you'll
see
there's at least one instance where they're quite useful even when you don't have
a
section element selected.
It would be nice to be able to use the editor's normal tools for splitting and joining XML elements to split and merge DocBook sections, but that doesn't seem to be an option, so you need to resort to some trickery when you need to perform this kind of surgery.
To split an existing section, all you need to do is select the paragraph that you
want to
begin the new section or subsection (use the Node path or Control-Up until the whole
para element is selected), and then choose DocBook -> Promote if you want
the paragraph to start a new section at the same level as the section it's part of,
or
DocBook -> Demote if you want it to become the first paragraph of a subsection.
If you don't want to think too hard, you can always manually cut and paste all the children into one section and then delete the other. If there are a lot of children to move, this gets tedious quickly, so we've found a trick that can save steps:
- Make sure the two sections you want to join are adjacent to each other, with the one you want to keep before the one you want to get rid of (this is mostly so these instructions make sense; once you get the hang of how this really works you can be more flexible).
- Select the first one (use the Node path or Control-Up until the whole
sectionelement is selected). - Now the tricky parts begin: Choose Select -> Select All Children (you'll see a bunch of selection boxes around all the individual elements that make up that section).
- Choose Edit -> Copy(you can't cut a complex selection like this, so we'll come back and delete it later).
- Select the
titleelement of the second section you want to join (click on it and use Node path or Control-Up until thetitleelement is selected). - You can now choose Edit -> Paste (because the first item in your complex
multiple-selection copy, being the
titleof the firstsection, is the same type as the item you now have selected, the operation is legal). This will replace the second section's title with the first section's title, and insert all the other elements of the first section at the beginning of the second section. Congratulations, you've just merged the sections. - Now select the entire first section again and delete it (because you couldn't cut in step 4).
This seems a little bizarre, but provides an interesting illustration of the subtleties of the ways selections, copy and paste work in XMLmind. Once you develop a deep understanding of how this trick works, you'll be able to come up with similar tricks to efficiently accomplish other goals. And then maybe you should get a job at Pixware...
Working with Multiple Files and Includes
When working on a really sizeable document, such as a book, you are probably going to want to separate it into multiple files. (O'Reilly sensibly wants each chapter in a separate file, for example.) Although XMLmind can cope with this just fine, we don't yet know of any way to set up the include relationship using the free standard edition, so we always use a plain text editor to do this part.
The best practice is to have the book file just contain the book metadata, and no actual content. All content is attached by inclusion, using the modern XInclude mechanism (see Using XInclude for more details on this standard).
So a simple book file would look something like this:
<?xml version="1.0"?> <!DOCTYPE book PUBLIC "-//OASIS//DTD DocBook XML V4.4//EN" "http://www.oasis-open.org/docbook/xml/4.4/docbookx.dtd"> <book> <title>A Small Book Written in XML</title> <xi:include href="copyright.xml" xmlns:xi="http://www.w3.org/2001/XInclude" /> <xi:include href="preface.xml" xmlns:xi="http://www.w3.org/2001/XInclude" /> <xi:include href="setup.xml" xmlns:xi="http://www.w3.org/2001/XInclude" /> <xi:include href="mapping.xml" xmlns:xi="http://www.w3.org/2001/XInclude" /> <xi:include href="whereNext.xml" xmlns:xi="http://www.w3.org/2001/XInclude" /> </book>
Each of the chapter files (such as setup.xml in this example) is a
full-fledged XML document with its own headers:
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE chapter PUBLIC "-//OASIS//DTD DocBook XML V4.4//EN" "http://www.oasis-open.org/docbook/xml/4.4/docbookx.dtd"> <chapter id="chap-setup"> ... </chapter>
That's one of the things that makes XInclude nice: You can edit each individual file with an XML-aware editor, or you can work with the whole thing as a coherent whole. In XMLmind, when you open the book file, you'll see all of the content that gets included, so you can see what the book as a whole looks like (and how chapters get numbered, etc.), but the included content will be read-only, and displayed with a pastel blue background (you'll get a warning dialog about this, which you can turn off, but it might be a helpful reminder).
When you want to edit any of the included content, simply select part of it or put your insertion point there and choose Edit -> Reference -> Edit Referenced Document (or click the corresponding icon next to the Node path bar):
This will open a new tab editing that specific chapter file, in which you can make your changes. To get back to the book you can either switch tabs or choose Edit -> Reference -> Edit Referencing Document (the next icon to the left).
When you structure a document with XInclude this way, the XML id attributes
you assign to sections, figures, and the like are all part of a single global namespace,
so
you can perform cross-references between chapters with no problem (and XMLmind will
help you
with this through its ID selection interface as illustrated in Cross References). But this also means you need to be sure to
keep your IDs globally unique.
Comments
Sometimes you just want to leave a note for yourself or your coauthors in the document. XMLmind supports that, leveraging the normal comment syntax of XML. The Edit menu has a Comment submenu that you can use to insert a comment at, before, or after the node you're currently working on. (If the choices are grayed out, you probably have a range of text selected within a #text node; either just click to get back to an insertion point, or use the Node path to select a specific entity with which you want to associate the comment.)
Within XMLmind, the comment will show up with a pastel yellow background (as if someone used a highlighter pen on it). Most stylesheets will simply not display the comments at all, so you don't need to worry about them showing up in your final copy. The O'Reilly stylesheets used for producing author drafts display the comments in bright red to help us find areas of our books that still need attention.
Miscellany
Here are some other things that are worthy of your investigation, although we're not going to take the time to cover them in as much depth.
Be sure to explore the Character tool(another tab in the lower-right interface that includes the Attribute tool we've been discussing):
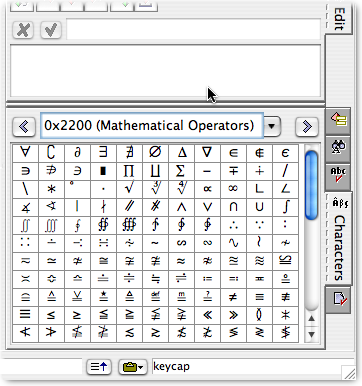
It's the first cross-platform place we've seen something that comes close to Mac OS X's convenient character palette for exploring the Unicode space and selecting the right special symbol you need to insert into your document. You can also use your platform-normal keyboard equivalents for special characters you happen to know, but there are way more useful symbols in the Unicode space than you can access from any keyboard. Just click one of the characters in the table to insert it into your document in a cross-platform, XML-safe way.
Also found in this set of tabbed panes are a spelling checker (the Spell tool), text find-and-replace system (the Search tool) and validation error list. The Attributes tool itself has more features than we've covered for viewing and editing the XML attributes of the currently-selected document node. And if you want to learn a bit more about the legal structure of the selected node itself, you can choose Show Content Model from the Help menu.
If you find better ways of doing anything we've talked about, or anything cool we simply didn't mention at all, please let us know! We're well aware there's a lot more to discover and share about this excellent tool.
Feel free to download the source DocBook XML version of this article, along with its figs directory, if you'd find it useful as an example of anything we've discussed here, or as a starting point for your own work.